Bio-informatique
ALPACA, le projet européen qui vise à changer la représentation des génomes
Date:

Le projet ALPACA consiste à développer de nouvelles approches algorithmiques permettant de représenter des génomes non plus sous forme de telles séquences "à plat" mais sous la forme de graphe.
Le projet concerne les énormes masses de données générées par les séquenceurs. « On arrive à l’échelle de l’exabyte. Il faut donc trouver un autre moyen de stocker et de traiter les informations », précise Pierre Peterlongo, responsable de l’équipe GenScale au centre Inria de l'Université de Rennes. Ces données se présentent sous forme de séries de lettres (A, C, G, T) correspondant aux quatre nucléotides Adénine, Cytosine, Guanine, Thymine, c’est à dire les blocs qui constituent l’ADN. Pour l’instant, ces lettres sont stockées de façon séquentielle, les unes derrière les autres, dans un long fichier texte.
« Aujourd’hui, il est assez courant de séquencer plusieurs individus d’une même espèce. Il y a eu le projet 1000 Génomes pour cataloguer des variations génétiques chez l’être humain. Un projet 100 000 Génomes vient de commencer. Or, vous et moi nous avons le même génome à 99% ! Il est donc un peu dommage de stocker une information aussi redondante pratiquement deux fois dans deux fichiers de séquences texte qui se ressemblent autant. Pour éviter cela, l’idée de la "pangénomique" consiste à agencer l’information sous forme de graphe. La partie commune est stockée une seule fois et les variants sont représentés par des branches dans un graphe. De cette façon, on réalise d’énormes économies en stockage et en redondance. »
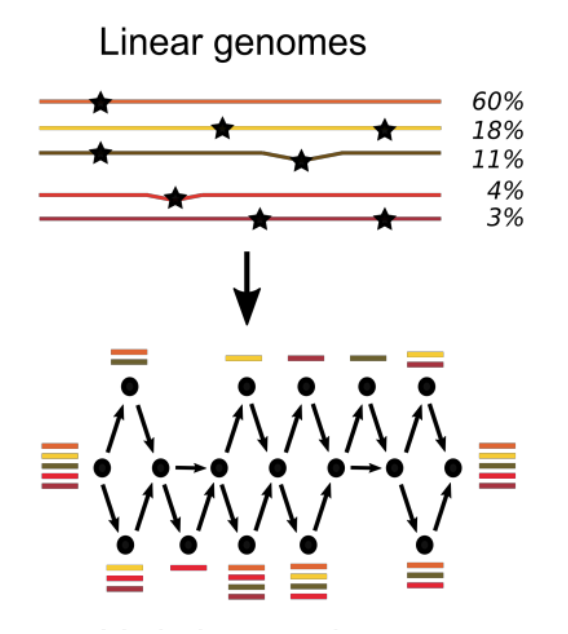
Et ce n’est pas tout. « On peut aussi utiliser ce type de structures pour dériver des connaissances biologiques. Sur 1000 individus, imaginons que certains aient un cancer. On va pouvoir identifier dans le graphe certaines zones plus spécifiques à cette maladie et ainsi mieux comprendre ses mécanismes. Par exemple : tels variants semblent impliqués, même si l’on ne sait pas encore comment. Alors on va se pencher dessus. Le graphe est un bon outil pour ce genre de travail. »
Cela dit, avec un génome humain composé de trois milliards de caractères, la navigation visuelle dans un graphe n’est guère adaptée. « Il faut des méthodes d’analyse statistique pour mettre en lumière les zones d’intérêt. » Les scientifiques veulent aussi réinjecter dans ces graphes toutes les annotations qui ont pu être faites durant les recherches sur le génome. À la clé : « une structure de données enrichie permettant de consigner des informations utiles. »
Inria et l’Institut Pasteur seront plus particulièrement en charge de la création de cette structure basée sur les graphes. « Nous développerons probablement un outil commun que nous mettrons ensuite à disposition de toute la communauté. Nous nous intéressons aussi à l’exploitation algorithmique de cette structure. »
Deux défis principaux se présentent. Le premier tient dans la masse des données. Il faut trouver un moyen de stocker plus efficacement l’information pour être à la fois très agressif sur la compression et ultra rapide sur les requêtes dans ces graphes. Si l’on compresse trop, la décompression va prendre beaucoup de temps avant que l’on puisse lancer la requête. » Toute la difficulté consiste à identifier le meilleur compromis.
Deuxième problème : la mise à jour. « Une fois que vous avez construit un graphe de 1000 individus, quand vous en ajoutez un 1001e, vous n’avez pas envie de devoir tout reconstruire à zéro. Or, pour l’instant, nous n’avons pas de structure de données qui soit suffisamment malléable pour permettre une mise à jour facile. »
Plus en aval dans le projet ALPACA, « d’autres chercheurs s’intéressent à cette nouvelle structure basée graphe dans le cadre de travaux sur leurs propres données. Bio-informaticienne, et responsable de l’équipe Erable, au centre Inria de Lyon, ma collègue Marie-France Sagot, par exemple, travaille plus étroitement que moi sur les données biologiques. Elle cherche des solutions pour faire parler un type de données particulier. »
La technologie issue de ces travaux s’adresse aussi aux industriels du séquençage. « Ils s’y intéressent à deux titres. D'une part, parce qu’elle permettrait de soulager leurs infrastructures de stockage souvent saturées. D'autre part, parce qu’ils pourraient ainsi fournir à leurs clients des données génomiques possédant des structures plus immédiatement exploitables. »

« L’idée derrière ce dispositif de bourses, c’est de fédérer un ensemble d’instituts de recherche en Europe autour d’une problématique scientifique émergente en finançant un gros pool de thèses de doctorat pour former ainsi la nouvelle génération de chercheurs, résume Pierre Peterlongo, responsable de l’équipe GenScale au centre Inria de l'Université de Rennes. En deux mots, chaque étudiant dispose d’un encadrant dans un laboratoire, de plusieurs coencadrants dans d’autres lieux, y compris chez un partenaire industriel, et il effectuera une partie de sa recherche dans le laboratoire d’un partenaire. À cela s’ajoutent des écoles d’été, des séminaires, etc. De cette façon, les jeunes chercheurs auront l’occasion de bien se connaître. Ce qui, au final, contribuera à construire un réseau. Cela permettra aussi aux étudiants de se dégager du cadre un peu restreint de leur sujet d’étude et de se familiariser avec le travail des autres. Ils acquerront ainsi une vision plus globale de la thématique de recherche. »
Dans ce contexte, le dispositif Alpaca va former quatorze étudiants en pangénomique computationnelle sur la période 2020-23. Coordonné par l’université de Bielefeld (Allemagne), le consortium comprend 23 partenaires académiques et industriels dont : CWI (Pays-Bas), l’Université de Pise, l’Université Milan-Bicocca (Italie), l’Université Heinrich Heine de Düsseldorf (Allemagne), l’Université Comenius de Bratislava, Geneton SRO (Slovaquie), l’Université d’Helsinki (Finlande), l’Université de Cambridge (Royaume-Uni), Inria, le CNRS, l’Institut Pasteur (France) ainsi que le Laboratoire européen de biologie moléculaire (Allemagne). Le financement se monte à 3,67 millions d’euros.