Cognition
Rachel Bawden améliore les modèles de traduction automatique
Date:

Rachel Bawden a basculé dans la linguistique informatique après son Bachelor of Arts (BA) en français et linguistique obtenu à l’université d’Oxford, dans son pays d’origine : « Je souhaitais m’orienter vers un cursus plus technique qui offrait davantage d’applications concrètes, explique-t-elle. J’ai donc suivi une 1re année de master Sciences du langage, parcours Ingénierie linguistique, à l’université Sorbonne Nouvelle, puis deux ans à l’université Paris Diderot qui proposait, elle aussi, un parcours Linguistique informatique. » À l’issue de son master, Rachel se lance dans un doctorat au sein du Laboratoire d'informatique pour la mécanique et les sciences de l'ingénieur (LIMSI), devenu le Laboratoire Interdisciplinaire des Sciences du Numérique (LISN).
En 2018, elle soutient à l’Université Paris-Saclay sa thèse intitulée Au-delà de la phrase : traduction automatique de dialogue en contexte qui s’intéressait à l’amélioration de la prise en compte du contexte par les systèmes de traduction automatique :
Verbatim
Certains mots (et donc les phrases qui les contiennent) ne peuvent se comprendre sans contexte. Je pense par exemple au mot "avocat" qui a deux sens bien distincts en français. Idem pour le mot anglais "bank" qui désigne à la fois la banque et la rive, détaille la jeune chercheuse. La question se pose de savoir comment prendre en compte le mieux possible les informations contextuelles présentes dans le texte ou ses métadonnées.
Chargée de recherche au sein de l’équipe-projet ALMAnaCH
L’excellence de ses travaux lui vaudra le Prix de thèse 2019 de l’ATALA (Association pour le traitement automatique des langues). Depuis, elle collabore notamment avec l’équipe WILLOW sous la forme de l'encadrement d’un doctorant, Matthieu Futeral, intéressé par l’intégration du contexte visuel dans la traduction automatique.

Après sa soutenance, Rachel Bawden intègre l’Institute for Language, Cognition & Computation (ILCC) de l’université d’Édimbourg en tant que postdoctorante. Elle y mène des recherches sur la traduction automatique de langues "à faibles ressources", pour lesquelles il existe peu de données pour entraîner les modèles d’apprentissage automatique. La chercheuse s’intéresse en particulier à deux langues indiennes : le gujarati, parlé principalement dans l’ouest, et le tamoul, parlé au sud.
C’est en 2020 que Rachel rejoint l’équipe-projet ALMAnaCH du centre Inria de Paris, dirigée par Benoît Sagot, en tant que chargée de recherches en Natural Language Processing (NLP) et Machine Translation (MT). Un choix qui ne doit rien au hasard :
Verbatim
Cinq ans auparavant j’avais effectué mon stage de master au sein de l’équipe qui l’a précédée, Alpage (UMR Inria / Université Paris-Diderot). Rejoindre ALMAnaCH s’est fait assez naturellement, raconte la chercheuse. J’étais par ailleurs attirée par la recherche publique qui est pour moi synonyme d’une forme de liberté et de stabilité, surtout lorsqu’on exerce un métier-passion. Inria m’offrait un environnement de travail où il était possible de mener ses recherches sur un temps long, sans pression de résultats immédiats puisque c’est bien la qualité et l’aboutissement du travail qui priment.
Au sein de l’équipe-projet ALMAnaCH, Rachel Bawden participe à de nombreux projets de recherche dont MaTOS (Machine Translation for Open Science). Soutenu par l’Agence nationale de la recherche (ANR), celui-ci vise à « développer de nouvelles méthodes de traduction automatique intégrale pour les documents scientifiques en français et en anglais ainsi que des métriques automatiques pour évaluer la qualité des traductions produites ». La chercheuse est également impliquée dans un autre projet ANR, TraLaLaM, destiné à explorer l’utilisation de grands modèles de langue (LLM) pour la traduction automatique des langues à faibles ressources, notamment les dialectes et les langues régionales. Ces objectifs s’approchent de ceux du Défi Inria COLaF qui consiste à rassembler des corpus de texte, de parole et de langue des signes pour le français et les autres langues de France dans toute leur diversité.
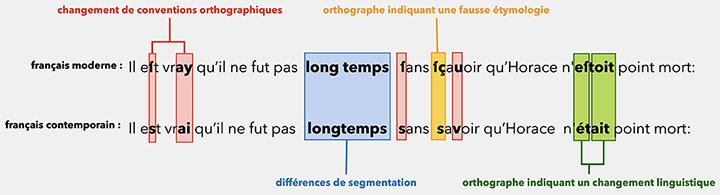
Rachel est par ailleurs active au sein de l’institut PRAIRIE (PaRis AI Research InstitutE) en tant que titulaire d’un poste de chaire "tremplin" : « J’y travaille à rendre plus robustes les modèles de traduction automatique afin qu’ils traitent de manière affinée des textes aux variations linguistiques élevées. Ces variations se rencontrent notamment sur les réseaux sociaux où l’utilisateur va s’exprimer en usant d’acronymes, de phrases incomplètes ou en commettant des fautes d’orthographes » explique-t-elle. Pour l’accompagner dans ses travaux, l’institut finance une doctorante, Lydia Nishimwe, qu’elle coencadre avec Benoît Sagot. « Ces recherches partagent des similarités avec d’autres travaux, pourtant sur un genre de texte très différent, menés avec mes collègues sur le traitement automatique du français du XVIIe siècle et notamment sur sa normalisation vers le français contemporain » souligne la chercheuse.
Comme l’illustre la diversité des projets d’ALMAnaCH, le traitement automatique des langues, sous-domaine de l’intelligence artificielle, est un secteur en ébullition :
Verbatim
C’est un domaine qui connaît des changements extrêmement rapides, témoigne Rachel. Et les avancées et les innovations font apparaître de nouvelles problématiques. Récemment, la question des types de données utilisés pour développer et entraîner les modèles a levé des interrogations d’ordre juridique par exemple.
Quel conseil donnerait la chercheuse à des jeunes qui souhaiteraient s’orienter dans le domaine du traitement automatique des langues ? « Oser changer de parcours, avoir de l’audace et ne pas hésiter à se réorienter si on en ressent le besoin. Avant d’entreprendre mes études de master, je me rappelle d’ailleurs avoir reçu en cadeau d’anniversaire le livre Speech and Language Processing de Daniel Jurafsky et James Martin. La lecture de cet ouvrage qui s’intéresse au traitement des langues a été pour moi comme un signe venu confirmer que j’avais enfin trouvé ma voie », se remémore-t-elle.
