Cognition
Rachel Bawden working to enhance machine translation models
Date:

British-born Rachel Bawden converted to computational linguistics after obtaining her Bachelor of Arts (BA) in French and Linguistics from Oxford University. ‘I wanted to take a more technical path that would offer more practical applications,’ she tells us. ‘I therefore took the 1st year of the Language Science Masters with a specialisation in linguistic engineering at Sorbonne Nouvelle University, followed by two years at Paris Diderot University, which also offers a computational linguistics programme.’ On completing her Masters, Rachel began a PhD at the LIMSI laboratory, now known as the Interdisciplinary Laboratory of Digital Sciences (LISN).
In 2018, she defended her thesis at Paris-Saclay University entitled Going beyond the sentence: Contextual Machine Translation of Dialogue, focused on improving how machine translation systems handle context:
Verbatim
Certain words (and therefore the sentences they are found in) cannot be understood without context. Take the French word “avocat” for example, which has two distinct meanings [“avocado” and “lawyer”], or the English word “bank” ["river bank" or "financial institute"]. The challenge is how best to integrate contextual information present in the text or its metadata.
Researcher at Inria, Paris in the ALMAnaCH team
Her outstanding work was awarded the 2019 Thesis Prize by the ATALA (Association for Natural Language Processing). Since then, she has continued along this research axis as part of a collaboration with the WILLOW project-team, in the form of joint supervision of PhD student Matthieu Futeral, who explores the integration of visual context in machine translation.

Following her PhD, Rachel Bawden joined the University of Edinburgh’s Institute for Language, Cognition & Computation (ILCC) as a postdoctoral student. She carried out research into the machine translation of ‘low-resource’ languages, for which there is little data to train models. The researcher focused on two Indian languages in particular: Gujarati, spoken mainly in the west of India, and Tamil, spoken in the south.
In 2020, Rachel joined the ALMAnaCH project-team led by Benoît Sagot at Inria Paris, as a ‘chargée de recherches’ in Natural Language Processing (NLP) and Machine Translation (MT), a move which was no coincidence:
Verbatim
Five years previously, I carried out my Masters internship at Alpage (Inria/Paris-Diderot University Joint Research Unit), ALMAnaCH’s predecessor. Joining ALMAnaCH felt natural to me,’ she tells us. ‘I was also attracted to public research, which for me represents a form of freedom and stability, especially for a profession I do out of passion. Inria offered me a working environment in which I could carry out my research over the long term, without as much pressure for immediate results, because the quality and culmination of work is what counts.
Rachel Bawden contributes to numerous research projects in the ALMAnaCH project-team, including MaTOS (Machine Translation for Open Science). Supported by the French National Research Agency, the ANR, the aim of the project is to ‘develop new approaches to machine translation for whole scientific documents in French and English, in addition to automatic metrics to assess the quality of the translations produced.’ The researcher is also involved in another ANR project, TraLaLaM, dedicated to exploring the use of large language models (LLMs) for the machine translation of low-resource languages, and in particular dialects and regional languages. These aims are similar to those of the COLaF, an Inria challenge (DEFI) dedicated to the collection and creation of text, speech and sign language corpora for French and the other languages of France in all their diversity.
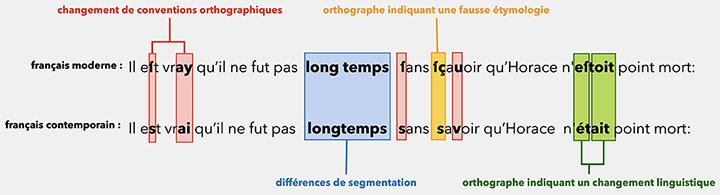
Rachel is also an active member of the PRAIRIE Institute (PaRis AI Research InstitutE) as the holder of a ‘springboard’ chair. ‘My research within PRAIRIE focuses on the robustness of machine translation models, in order to produce high-quality models for texts displaying high degrees of linguistic variations. Such texts can be found notably on social networks, where users will typically write using acronyms, incomplete sentences or spelling mistakes,’ she explains. To support her research, the institute funds a doctoral student, Lydia Nishimwe, who Rachel co-supervises with Benoît Sagot. ‘Despite dealing with a very different type of text, this research shares similarities with another research topic I have had the opportunity to explore in collaboration with colleagues on the automatic processing of 17th-century French and specifically its normalisation into contemporary French,’ she points out.
As the diversity of ALMAnaCH projects demonstrates, natural language processing, a sub-field of artificial intelligence, is a booming sector.
Verbatim
The field is undergoing extremely rapid changes,’says Rachel, ‘and with its progress and innovations come new issues. Legal questions have been raised recently, for instance, over the type of data used to develop and train models.
What advice does the researcher have for young people interested in the field of natural language processing? ‘Dare to change your path, be courageous and don’t hesitate to change direction if you need to. Before starting my masters, I was given a book for my birthday entitled Speech and Language Processing by Daniel Jurafsky and James Martin. Reading this book was like a sign confirming I had found my vocation’.
