Security and confidentiality
How mathematics is making online privacy more secure
Date:
Date:
Changed on 19/10/2021
First introduced by researchers in the United States in 2006 (Dwork et al), differential privacy built on research by 20th century statisticians that aimed to ensure the confidentiality of private information when publishing data from a statistical database, such as census records. Any data release of this kind must strike a balance between the utility of the data and the privacy of the people providing it. By adding statistical “noise” generated by random data to the data according to its level of sensitivity, differential privacy aims to guarantee that attackers will not be able to obtain any more information about the data providers than they already have. Thus, both utility and privacy are satisfied, and more people are likely to agree to participate in statistical databases.
To achieve this, the curator of the database must apply the right number, or amount of “noise”, to the differential privacy equation, according to their assessment of the risk of a privacy breach. This apparently simple principle is more complex in practice. “Even an expert may find it difficult to know whether the way they have applied differential privacy will be effective, because in its current form its mechanism is too mathematical to be easy to explain,” says Natasha Fernandes, Research Associate at UNSW Canberra. “When a doctor tells a patient that they need surgery, they also inform them about the risks involved, but we don’t have a simple way of explaining risk in data privacy. That was one of the issues I wanted to fix in my doctoral research.”
She also aimed to extend differential privacy so that it can be applied to modern datasets such as text documents in a meaningful, interpretable way. With Catuscia Palamidessi, Director of Research at Inria and the Institut Polytechnique de Paris, and Annabelle Mciver, Professor at Macquarie University in Sydney, as her co-supervisors (see box article), Natasha Fernandes was able to build on their work on local differential privacy, where “noise” is applied to the data provided by a single user rather than to the results of a query to a database as a whole. “Local differential privacy is a major new direction in privacy that is increasingly being used by giants like Google or Apple,” explains Catuscia Palamidessi. “Our work has made it treatable in metric data domains by taking into account the distance between data in the differential privacy formula, so that it offers much more utility for the same amount of privacy.”
Image

Verbatim
Local differential privacy is a major new direction in privacy that is increasingly being used by giants like Google or Apple.
Auteur
Poste
Research director Inria
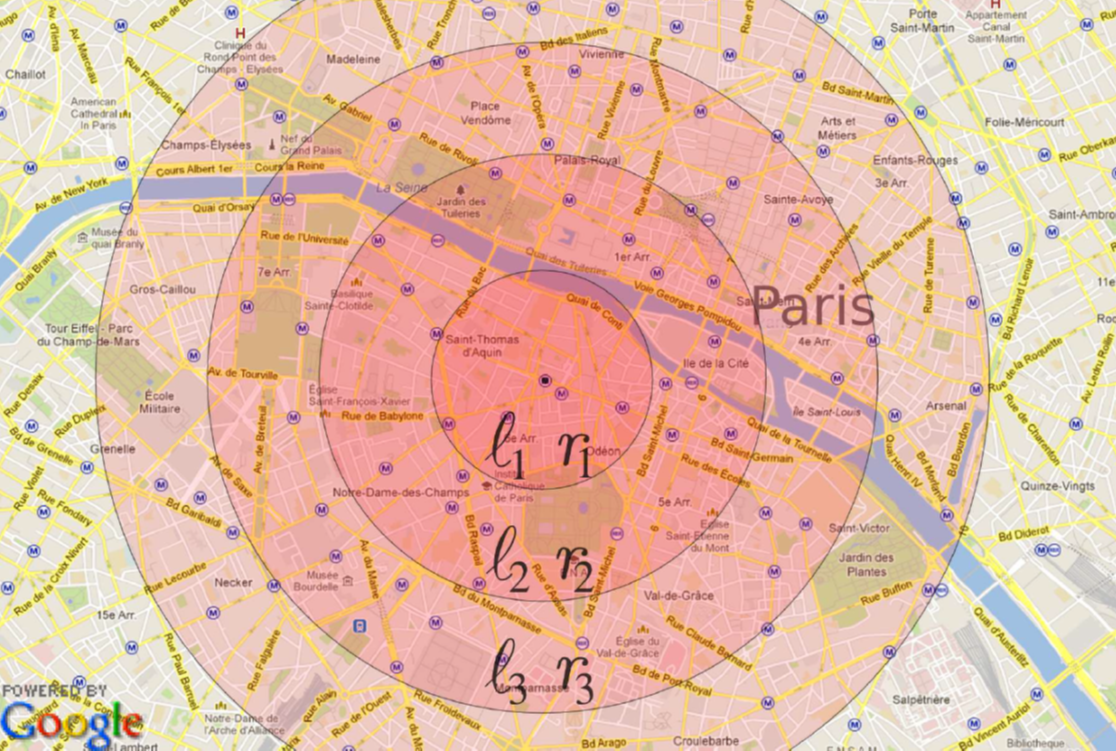
Catuscia Palamidessi and her partners at France’s CRNS and École polytechnique have already applied their work to Location Guard. This navigation app, available on platforms including Chrome, Firefox and Opera, allows its more than 200,000 users to hide their exact location. For example, a tourist in Paris might not want to reveal that they are visiting the Moulin Rouge cabaret; the app will locate them in a wider area, including say the Notre Dame Cathedral or the Louvre.
Natasha Fernandes’ work has taken local differential privacy with metrics a step further by applying it to text documents in such a way that a computer could understand what the text was about without being able to identify its author. “The literature suggested that it was impossible to apply differential privacy to texts, so that made me even more determined!” recalls Natasha Fernandes. “To ensure machine learning was unable to detect the writing style of a given author, we added a distance measure and showed mathematically that it was possible to keep the classification of the document and yet protect against identification.”
This extension has many potential applications: a whistleblower would be able to bring information to light while remaining anonymous, for example, an intelligence agency could protect classified material when publishing sensitive documents, or a retailer could analyze consumer emails without knowing who they were. “There is a great deal of interest in privacy right now and, as the first to successfully apply local differential privacy to text datasets, Natasha’s work has helped solve a very difficult problem,” says Annabelle McIver. So much so that it has sparked interest at Amazon, where researchers have taken it up and are now organizing biannual workshops on text privacy, as a result of Natasha Fernandes’ original research.
Image

Verbatim
Explanation is crucial for privacy mechanisms to do the jobs that they are supposed to do, and Natasha’s research is a major step forward on that road.
Auteur
Poste
Professor Macquarie University of Sydney
Her work has also advanced understanding of one of the fundamental techniques for applying differential privacy, the Laplace mechanism, which is a simple and efficient way of adding “noise” to preserve privacy, and can be tuned to provide the desired level of privacy. The 2006 research (Dwork et al) designed differential privacy around Laplace, but although this fundamental mechanism, was being commonly used to protect privacy, there was limited research on whether it actually had good utility. “Laplace is crucial because it is such fundamental part of differential privacy,” explains Natasha Fernandes, “and my work confirmed that it really does provide ‘universal optimality’, that is, the highest accuracy of all privacy mechanisms to the widest variety of consumers.”
Her research also found that other privacy mechanisms, currently in use by Google, also provide optimality in some situations, overturning an impossibility result which claimed that this could not be the case.
Image

Verbatim
In the future, this could lead to a way of illustrating risk by adding a graphic to online consent forms or giving consumers the ability to set their own parameters.
Auteur
Poste
Former PhD student, research associate at UNSW Canberra
This confirmation is an important step forward in allowing Natasha Fernandes to achieve one of her key objectives: making the risks of privacy breaches easier to understand. “If people need a math degree to understand the level of risk of a privacy breach, that doesn’t instill confidence in them to be feel comfortable about sharing their data,” says Annabelle McIver. “Explanation is crucial for privacy mechanisms to do the jobs that they are supposed to do, and Natasha’s research is a major step forward on that road.” Her work has provided a framework that can describe all kinds of attacks and show which mechanisms protect against which kinds of attack. “Today it is difficult for consumers to understand if they are told that a privacy mechanism has been parametrized by 3 or 4, for example, but if I can ask what kind of attack they are worried about, I can model that and tell them how likely it is that their secret will be revealed,” explains Natasha Fernandes. “In the future, this could lead to a way of illustrating risk by adding a graphic to online consent forms or giving consumers the ability to set their own parameters.” And she concludes, “My hope is that my research will eventually make it simple for consumers to compare privacy systems and make a clear, informed choice.”
Catuscia Palamidessi and Annabelle McIver have been working together for several years and their collaboration was an opportunity for Natasha Fernandes to benefit from expertise in two fields and on two continents. Co-supervision is fairly common in France, but rarer in Australia and Natasha Fernandes was the first doctoral student at Macquarie University to work in this way at Inria and École polytechnique. She spent 15 months at the campus in Paris before returning to Sydney to complete her research. “The Australian research environment tends to be quite isolated and my time in Europe gave me a whole different view of how science is conducted there,” she says. “And as my research covered several different fields, it was also a real bonus to be supervised by two leading experts.”
Her co-supervisors agree. “From a scientific perspective, different people have different skills, and Annabelle and I are very complementary, with my work on privacy and hers on formal methods,” says Catuscia Palamidessi. And Annabelle McIver adds, “There is a lot of research underway in Europe on differential privacy, so this was a wonderful opportunity for Natasha to meet and interact with many scientists. And of course, being able to work closely with her and Catuscia was great!”