Avec GuessWhat ?! quand l’humain joue, l’ordinateur s’initie au langage
Date:
« En machine learning, travailler uniquement sur des images ou sur du texte est assez classique. C’est lorsque l’on commence à mélanger les deux que les choses se compliquent. Et pourtant, image et texte sont intrinsèquement liés », indique Florian Strub, doctorant au sein de l’équipe-projet Sequel du centre Inria de Lille, commune avec le laboratoire CRIStAL (Centrale Lille, CNRS, Université de Lille). Depuis un an, l'équipe travaille, en collaboration avec l’université de Montréal, sur un projet de recherche en machine learning qui implique image et dialogue. Financé dans le cadre du projet international IGLU (programme CHIST-ERA), l’objectif est de montrer que le langage s'apprend en interagissant avec le monde extérieur. Pour ce faire, les chercheurs avaient initialement envisagé un cas pratique : la conception d’un robot assistant cuisinier. « Nous devions travailler sur l’interaction avec le robot, précise Florian Strub, doctorant au sein de l’équipe Sequel. Par exemple, il fallait qu’il comprenne des consignes telles que : "Prends la cuillère dans le troisième tiroir à gauche." L’ordinateur devait donc apprendre à compter et à se repérer dans son environnement. » C’est alors que les chercheurs ont eu l’idée de développer cet apprentissage à partir d’un jeu : GuessWhat ?!
Le principe : deux utilisateurs jouent ensemble, le premier sélectionne un objet dans une image, le second doit trouver l’objet en posant une série de questions : est-ce que l’objet est rouge ? Est-ce qu’il est à droite de l’image ? Est-ce que c’est une voiture ? Et ainsi de suite... Pour les chercheurs, l’objectif est de recueillir un maximum de parties jouées pour que l’ordinateur apprenne à son tour à poser les questions. « Les concepts de gauche et droite, de dénombrement ou même les couleurs sont des choses naturelles pour nous. Et pourtant, nombreux sont les modèles informatiques qui échouent à cette tâche. Avec GuessWhat ?!, nous construisons un environnement où l’ordinateur n’a d’autre choix que d'utiliser ces concepts pour réussir. Plus difficile encore, il doit combiner les notions acquises pour développer une suite de questions cohérente et retrouver l’objet caché. »
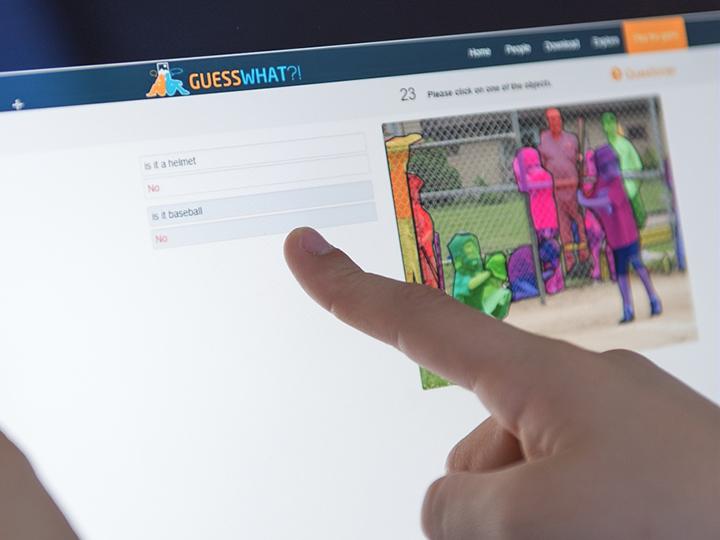
L’apprentissage automatique, c’est précisément l’expertise de Sequel. Les chercheurs de cette équipe-projet du centre Inria de Lille développent des algorithmes permettant de résoudre des problèmes séquentiels (par exemple une suite de questions) avec une méthode dite, de renforcement, c’est-à-dire en ayant une récompense à la fin. Avec GuessWhat ?!, la récompense est claire : retrouver l’objet caché dans l’image. Pour autant, le traitement de l’image reste un problème à part entière. C’est pourquoi, dès le début du projet, les chercheurs de Sequel ont collaboré étroitement avec le laboratoire MILA (Montreal Institute for Learning Algorithms ). « Il s’agit du plus grand laboratoire de recherche en matière de deep learning appliqué aux images, précise Harm de Vries, étudiant de l'université de Montréal participant au projet. Notre expertise, ce sont les systèmes de vision par ordinateur à grande échelle. L’équipe Sequel, elle, s’intéresse aux systèmes de dialogue. Ces deux compétences sont essentielles pour avancer dans le projet GuessWhat ?!. »
Le projet se déroule en trois phases. Les chercheurs ont d’abord recueilli des informations lors de 150 000 parties jouées en ligne par des humains. Puis, à partir de ces données, ils ont entraîné un ordinateur à poser des questions en imitant un humain. Le projet en est désormais à sa troisième phase : l’ordinateur joue lui-même à une infinité de jeux. Il pose les questions au fur et à mesure et apprend de ses erreurs. « Au début les questions de l’ordinateur n’ont aucun sens. Il doit apprendre petit à petit à poser des questions grammaticalement correctes, puis qui ont un sens. Il doit donc s’entraîner en faisant des milliers d’essais. Pour cela, nous avons créé une seconde intelligence artificielle qui répond par oui ou par non à ces questions. Les deux ordinateurs interagissent comme dans une partie d’échec. À un détail près ! Ils ne s’affrontent pas mais collaborent… » Si, in fine , un joueur pense qu’il joue contre un humain et non contre un ordinateur, les chercheurs auront réussi leur pari.
Dans nos modèles, l’ordinateur apprend à développer une stratégie, et c’est une première dans ce type de scénario.
D’ores et déjà, les résultats de l’ordinateur sont surprenants. Sur ce type de tâche, un humain arrive à trouver en général l’objet près de neuf fois sur dix. Avec les algorithmes les plus basiques, un ordinateur obtient 35 à 40% de réussite. Avec les derniers modèles conçus dans le cadre du projet GuessWhat ?!, l’ordinateur arrive à un score de 55% de réussite et d’après les chercheurs, ce n’est qu’un début. « Quand nous analysons les questions posées, nous nous apercevons que l’ordinateur comprend la notion de gauche et de droite et la plupart des relations entre les objets. Il a en revanche encore du mal à poser des questions en ce qui concerne les couleurs. Mais la vraie réussite est qu’il enchaîne les questions selon un sens logique. Dans nos modèles, l’ordinateur apprend à développer une stratégie, et c’est une première dans ce type de scénario. »
Ce beau succès a déjà valu à l’équipe des retombées prestigieuses. De nombreuses entreprises du Web suivent de près ce projet de recherche. Et l’équipe créatrice du jeu vient d’obtenir deux publications d’articles au CVPR et à l’IJCAI, parmi les plus importantes conférences internationales dans les domaines respectifs de la vision et de l’intelligence artificielle. « C’est une belle reconnaissance. Cela nous prouve que nous sommes sur la bonne voie et que ce problème vaut la peine d’être étudié », conclut Florian Strub.